Prof. Dr. Annette Hautli-Janisz und Prof. Dr. Steffen Herbold zeigen eine Grafik aus ihrer neuen Studie.
Ein interdisziplinäres Team um Steffen Herbold, Professor für AI Engineering, und Annette Hautli-Janisz, Professorin für Computational Rhetoric and Natural Language Processing, hat untersucht, wer bei politischen Fragen aus der Gesellschaft die authentischeren und relevanteren Antworten liefert: der Mensch oder die Maschine. Basis hierfür ist die britische Talkshow Question Time der BBC, eine der meistgesehen politischen Talkshows in Großbritannien. Auf dem Podium sitzen mehrere Gäste aus Gesellschaft und Politik. Die Fragen stellt das Publikum. Das Format lebt von seinem Live-Charakter, das heißt, es verlangt rhetorisches Geschick und Schlagfertigkeit.
„Ausgangspunkt unserer Studie war die Tatsache, dass wir beobachtet haben, dass Sprachmodelle immer besser darin geworden sind, einen vorgegebenen Stil zu imitieren“, erklärt Prof. Dr. Herbold. So kann die generative KI inzwischen sprachlichen Stil und politische Parteilichkeit vortäuschen. „Sprachmodelle sind damit in der Lage, gezielte politische Kommunikation zu generieren und damit die öffentliche Meinung zu beeinflussen“, sagt der Informatiker.
Kern der Studie: Authentizität der Antworten
Das Passauer Team wollte wissen: Wie täuschend echt ist diese Kommunikation? Kann sie Menschen überzeugen? Um das zu testen, haben die Forschenden einen Datensatz aus verschriftlichten Fragen und Antworten von 30 Sendungen aus der Zeit von 2020 bis 2022 ausgewertet und daraus 119 Fragen mit mehr als 500 Antworten extrahiert. Das Sprachmodell ChatGPT 4 Turbo sollte dieselben Fragen beantworten, mit der Vorgabe, dass die Maschine den sprachlichen Stil der Gäste in einer öffentlichen Debatte imitieren sollte. „Das betrifft das Kriterium der Authentizität, also den Kern unserer Studie. Gemeint ist die Frage, ob eine Antwort wirklich so in einer Live-Situation gefallen sein könnte“, erklärt Ko-Autorin Prof. Dr. Hautli-Janisz.
Die einzelnen Antworten der KI und die der Gäste hat das Forschungsteam in einer repräsentativen Studie insgesamt 948 britischen Bürgerinnen und Bürgern zur Bewertung vorgelegt. Die Teilnehmenden wussten nichts vom Einsatz von KI. Einigen Befragten wurde eine echte, anderen eine maschinell generierte Antwort präsentiert. Wieder andere sollten die maschinelle und die echte Antwort vergleichen oder die Antwort einem prominenten Sprecher zuordnen.
Die Ergebnisse im Überblick:
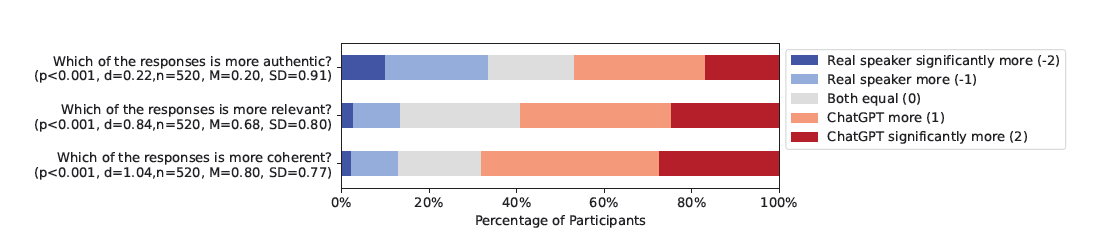
Warnung vor möglichen Folgen
„Problematisch ist insbesondere, dass Antworten, die inhaltlich abweichen, als authentisch eingestuft werden. Denn dann sind wir mit der Situation konfrontiert, dass die KI-Technologie zur gezielten Fehlinformation über den Standpunkt des Sprechers eingesetzt werden kann“, erklärt Prof. Dr. Hautli-Janisz. „Unsere Studie zeigt zweierlei: Sprachmodelle können dazu gebracht werden, einen sinnvollen Beitrag zu öffentlichen Debatten zu leisten. Es ist aber dringend notwendig, die Öffentlichkeit über den potenziellen Schaden aufzuklären, den dies für die Gesellschaft haben kann“, sagt Prof. Dr. Herbold. Ein unregulierter Einsatz von KI-Technologien in der politischen Kommunikation könnte verheerende Folgen haben.
Öffentliche Wahrnehmung
Die Forschenden befragten die Teilnehmenden auch nach ihrer Haltung zum Einsatz von generativer KI in öffentlichen Debatten. Die Mehrheit gab an, mit Technologien wie großen Sprachmodellen vertraut zu sein, befürwortete auch deren Einsatz, zweifelte allerdings an deren Nutzen in öffentlichen Debatten. Bei der Frage nach Regulierung gab es ein gemischtes Meinungsbild. Die Forschenden wollten wissen, ob sich daran etwas ändert, wenn die Befragten von den maschinell generierten Antworten in dem Experiment erfahren. Bei der Mehrheit änderte sich nichts. Doch mit Blick auf die Transparenz zeigte sich eine klare Tendenz: Mehr als 85 Prozent der Teilnehmenden forderten, dass der Einsatz von KI-Technologien offengelegt werden müsse und dass darüber informiert werden müsse, wie diese Technologien entwickelt werden.
Die Studie mit dem Titel “LLM-impersonated debate contributions are more authentic, relevant and coherent than their original: A representative study using BBC1’s Question Time“ ist in dem Journal PLOS One erschienen. Es handelt sich dabei um eine internationale, multidisziplinäre Online-Fachzeitschrift der Public Library of Science (PLOS).
Über das Autoren-Team
Prof. Dr. Steffen Herbold ist Inhaber des Lehrstuhls für AI Engineering an der Universität Passau. In seiner Forschung untersucht er schwerpunktmäßig die Qualität von KI-Modellen. Für die Studie setzte er gemeinsam mit seinem Mitarbeiter Dr. Alexander Trautsch die statistische Auswertung und eine Plattform für die Datenerhebung auf. Zusammen mit Prof. Dr. Hautli-Janisz modellierte er das Studiendesign.
Annette Hautli-Janisz ist Juniorprofessorin für Computational Rhetoric und Natural Language Processing. Sie interessiert sich in ihrer Forschung dafür, wie sich die Argumentation der KI-gestützten Sprachmodelle entwickelt. In die Studie brachte sie neben der computerlinguistischen Analyse die Idee ein, den bereits vorhandenen Datensatz QT30 für die Studie zu nutzen. Es handelt sich dabei um den größten Datensatz zu politischen Debattensendungen und umfasst insgesamt 30 Episoden der britischen Talkshow „Question Time“ (QT). Gemeinsam mit ihrer Doktorandin Zlata Kikteva analysierte sie die echten und maschinell generierten Antworten aus linguistischer Perspektive.
















