Über die Geschichte der Sprachfamilien Amerikas ist nur wenig bekannt. Ein Team von Sprachwissenschaftlern der Universität Passau, des Max-Planck-Instituts für evolutionäre Anthropologie in Leipzig und der Pontifica Universidad Católica del Perú in Lima hat aus computergestützten und konventionellen Methoden der historischen Linguistik ein Verfahren entwickelt, das neue Erkenntnisse bringen könnte.
Es gibt zahlreiche Hypothesen zu den Verwandtschaftsbeziehungen zwischen ihnen, aber nur wenige werden von der wissenschaftlichen Gemeinschaft akzeptiert. Um eine mögliche gemeinsame Abstammung der im Amazonasgebiet gesprochenen Sprachfamilien Pano und Takana zu untersuchen, hat ein internationales Team von Sprachwissenschaftlerinnen und Sprachwissenschaftlerin nun einen integrierten Arbeitsablauf entwickelt, der computergestützte und konventionelle Methoden der historischen Linguistik kombiniert. Durch die Analyse hypothetischer Wortschatzvarianten, die Voraussagen zufolge von einer Sprachfamilie in die andere übertragen würden, fanden die Forscherinnen und Forscher deutliche Hinweise auf die gemeinsame Abstammung der beiden.
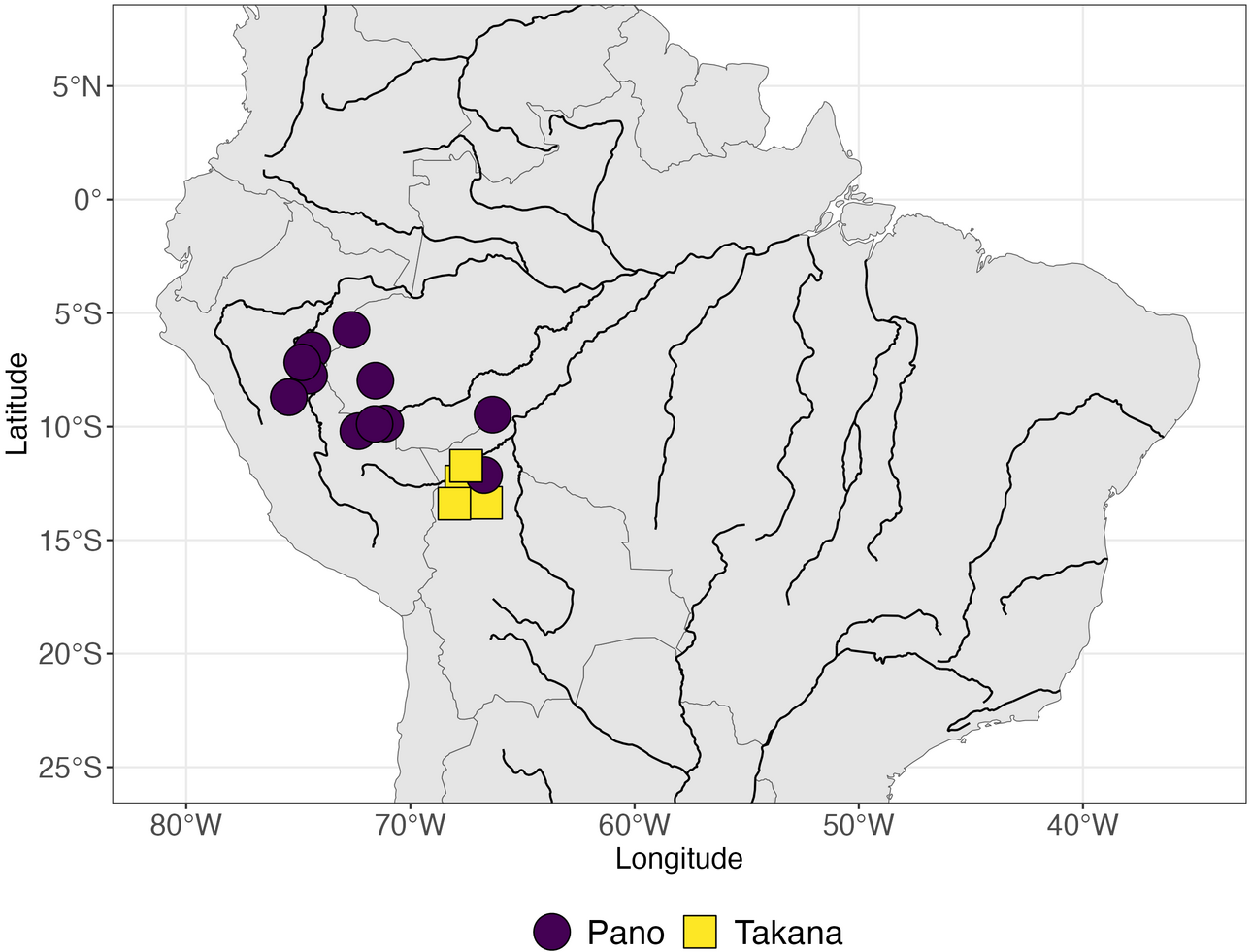
Die Forschenden des Max-Planck-Instituts für evolutionäre Anthropologie, der Universität Passau und der Pontificia Universidad Católica del Perú sammelten Daten zur Shipibo-Konibo-Sprache, einer Pano-Sprache, die im peruanischen Amazonasgebiet gesprochen wird. Sie verwendeten eine neue Computer-Implementierung einer bereits etablierten Methode zur Voraussage von Veränderungen in der Aussprache verwandter Wörter, die auf Ähnlichkeiten in der Aussprache zwischen verschiedenen Sprachfamilien beruht. Mit Hilfe dieser Methode und durch direkten Vergleich mit ihren Voraussagen identifizierte das Team mehr als 20 exakte Entsprechungen in den aufgezeichneten Daten. Die Ergebnisse der Studie sind im Dezember in der Fachzeitschrift Scientific Reports erschienen.
Entschlüsselung der Lautmuster

„Wir haben unsere Voraussagen anhand von Aufnahmen mit Muttersprachlerinnen und Muttersprachlern getestet. Dabei konnten wir die zuvor identifizierten Lautmuster bestätigen und fanden weitere Belege für die Rekonstruktion von drei neuen Lauten (Phonemen) für das Proto-Pano-Takana, den gemeinsamen Vorfahren der Sprachfamilien Pano und Takana“, kommentiert Erstautor Frederic Blum, Doktorand an der Universität Passau und am Max-Planck-Institut für evolutionäre Anthropologie in Leipzig. Die Autoren hoffen, dass ihr neuer Ansatz zur Untersuchung der Verwandtschaftsbeziehungen zwischen Sprachfamilien zu innovativen Hypothesen in der historischen Sprachwissenschaft führen wird, die das Wissen über die Geschichte der menschlichen Sprachen erweitern.
„Diese Studie hat unseren Werkzeugkasten in der computergestützten historischen Linguistik erweitert“, erklärt Johann-Mattis List, Inhaber des Lehrstuhls für Multilinguale Computerlinguistik an der Universität Passau und einer der Koautoren der Studie. „Durch die Anwendung einer formal definierten Methode auf eine Vielzahl von Sprachen aus unterschiedlichen Sprachfamilien sind wir jetzt in der Lage, die Beziehung zwischen zwei Sprachfamilien explizit auf der Grundlage einer bewährten und getesteten Methodik zu untersuchen.“ Die Autoren gehen davon aus, dass dieser innovative Ansatz in Zukunft auch auf andere Sprachfamilien übertragen werden kann und damit neue Konzepte zur Überprüfung von Hypothesen in der historischen Sprachwissenschaft ermöglicht.
Mehr Informationen:
Pressemitteilung des Max-Planck-Instituts für evolutionäre Anthropologie