Mensch und Roboter beim Candle-Light-Dinner. KI-generiertes Bild mit Hilfe von DeepAI und ChatGPT
Am Küchentisch sitzen ein Mensch und ein Roboter. Der Roboter ist mit einem großen Sprachmodell ausgestattet, also darauf trainiert, menschliche Sprache zu verarbeiten. Der Mensch sagt: „Bitte reich mir das Salz.“ Der Roboter tut es. Hat er die Bitte verstanden?
Nein, sagt Prof. Dr. Johann-Mattis List, Inhaber des Lehrstuhls für Multilingual Computational Linguistics. Doch, sagt sein Kollege Dr. Christian Bentz, Akademischer Rat am selben Lehrstuhl. Ihre Vorträge sind Teil der Ringvorlesung zum Thema „Künstliche Intelligenz – zwischen Hype und Realität“, die im Juni und Juli an der Universität Passau stattfand.
Große Sprachmodelle (Large Language Models, LLMs) verarbeiten Sprache mit Hilfe neuronaler Netze, die die Funktionsweise des menschlichen Gehirns nachahmen. Trainiert mit riesigen Mengen an Textdaten, erkennen sie Muster, Strukturen und Zusammenhänge. Dass LLMs – wie ChatGPT aus den USA oder Mistral AI aus Europa – inzwischen erstaunlich gut darin sind, auf menschliche Sprache zu reagieren, liegt daran, dass sich Sprachstrukturen offenbar ziemlich gut berechnen lassen.
Sprachmodelle sind Hochstapler – die Position von Prof. Dr. List
Für Johann-Mattis List bleibt das ein Trick. Sprachmodelle seien Hochstapler, die zwar überzeugend auftreten, aber nicht wirklich verstehen.
Er verweist auf das Gedankenexperiment des "chinesischen Zimmers" des Philosophen John Searle aus den 1980ern. Darin beantwortet eine Person in einem geschlossenen Raum chinesische Fragen auf Chinesisch – obwohl sie kein Chinesisch kann. Sie folgt einfach einer Anleitung in ihrer Muttersprache. Für Außenstehende entsteht der Eindruck, sie verstehe die Sprache. Doch das sei eine Illusion. „Searles Paper von damals liest sich wie eine aktuelle Debatte“, sagt Johann-Mattis List.
Ein weiteres Gedankenspiel lieferten die Linguistin Emily Bender und ihr Kollege Alexander Koller im Jahr 2020 mit dem „Octopus-Experiment“: Ein intelligenter Tiefsee-Oktopus hört heimlich zwei Menschen ab, die über ein Unterwasserkabel kommunizieren. Der Oktopus lernt, die eine Person zu imitieren, bis er eines Tages an einer Frage scheitert: „Ich werde von einem Bären angegriffen. Was soll ich tun?“ Der Oktopus kennt keine Bären – und entlarvt sich damit selbst.
Der amerikanische Sprachwissenschaftler Noam Chomsky argumentierte in den 1980er Jahren, das Erlernen von Sprache sei eine zutiefst menschliche Angelegenheit. Kinder lernten Grammatik selbst dann, wenn der Input begrenzt ist – ein Phänomen, das Chomsky als „poverty of the stimulus“ bezeichnete. Zwar gilt laut List dieses Argument heute als überholt, doch die zentrale Frage bleibt: Bedeutet können automatisch auch verstehen? List demonstriert den Gedanken mit einer Showeinlage:

Er selbst könne zwar bestimmte komplizierte Muster jonglieren, aber ob er diese Muster wirklich in all ihren Einzelheiten verstehe? Das sei eine andere Frage.
Sprachmodelle verstehen Sprache besser als Menschen, sagt Dr. Bentz
Zurück zum Eingangsbeispiel, das Sprachwissenschaftler Dr. Christian Bentz mitgebracht hat. Bentz ist Akademischer Rat am Lehrstuhl von Johann-Mattis List und interessiert sich für den Zusammenhang zwischen Information und Sprache.
In seinem ERC Projekt EVINE untersucht er die ersten Spuren der visuellen Informationskodierung - die Zeichen des Paläolithikums, manche davon bis zu 400 000 Jahre alt. Die ersten Zeichen dienten womöglich bereits als Gedächtnisstützen, viele tausend Jahre vor der Entwicklung der Schrift.
Zeitsprung ins Jahr 1950. Der Mathematiker Claude Elwood Shannon machte mit seiner Frau und Forscherkollegin Betty ein Experiment. Sie sollte fortlaufend die Buchstaben in Sätzen erraten. Sie machte sich dabei ihre natürliche Sprachintuition als Sprecherin des Englischen zunutze. Das Forscherpaar entwickelte so eine Methode, wie sich die Informationsdichte der Englischen Sprache berechnen lässt. Shannon definierte dazu die Entropie als ein Maß für den Informationsgehalt und die Unsicherheit.
Moderne Sprachmodelle haben die Fähigkeit perfektioniert, sprachliche Äußerungen vorherzusagen – und dementsprechend die Entropie zu minimieren. Sie berechnen Wahrscheinlichkeiten: Welches Wort kommt als nächstes? Dr. Bentz zufolge beherrschen sie das besser als Menschen – und zwar nicht nur im Englischen. Mit einem internationalen Team hat er anhand von Entropie und Redundanz Muster in Sprachen weltweit verglichen. Während sich in Verteilungen bei Buchstaben und Wörtern deutliche Unterschiede erkennen lassen, ähneln sich die Entropie-Werte der Wortteile in ganz unterschiedlichen Sprachen doch überraschend stark:
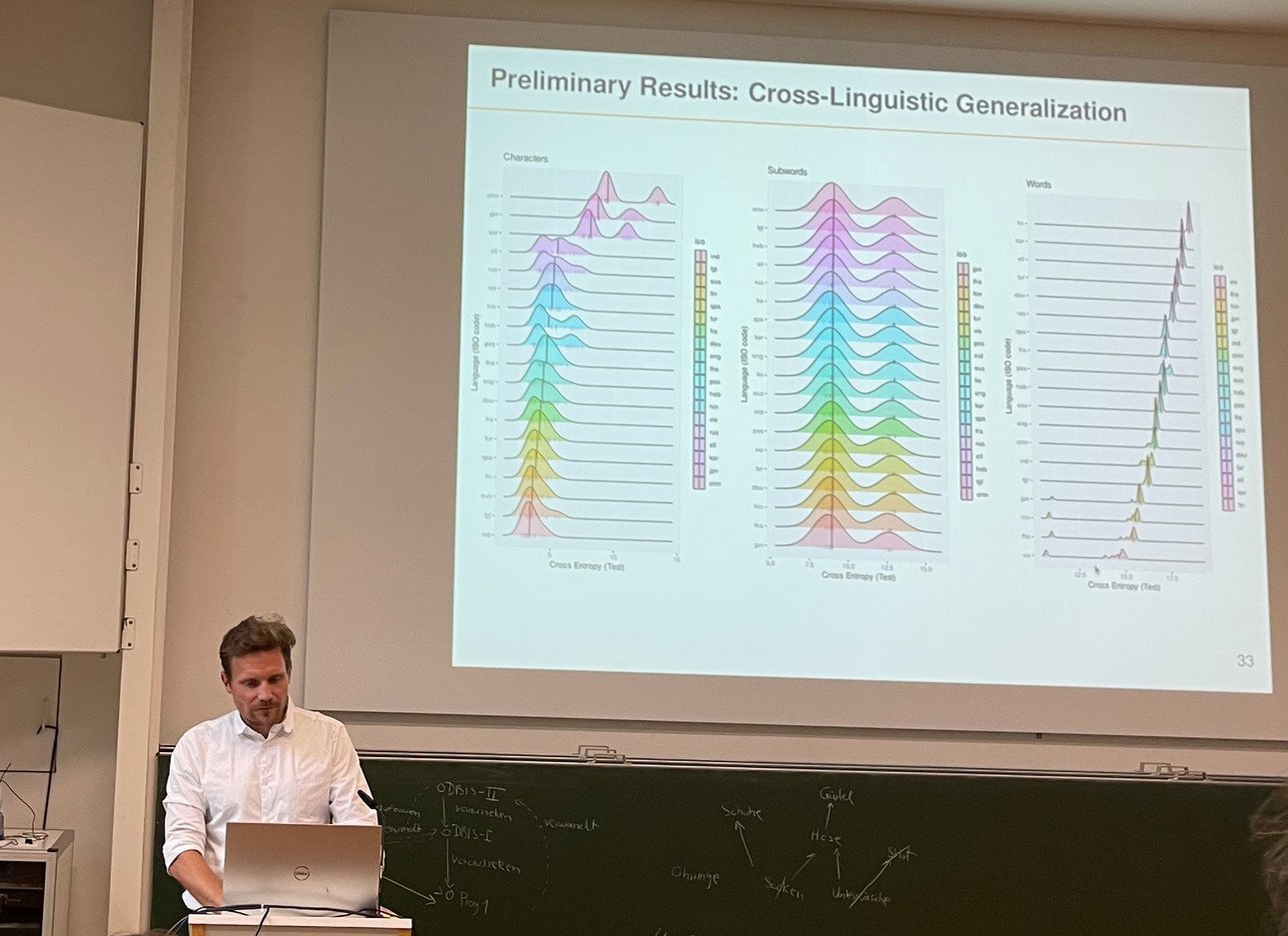
Deshalb sein Fazit: Ganz unterschiedliche Sprachen lassen sich mit den gleichen Methoden berechnen und modellieren. Und damit würden Sprachmodelle Sprachen zumindest besser vorhersagen können als Menschen. Aber ist statistisch exaktes Vorhersagen gleichzusetzen mit Verstehen?
Dr. Bentz kommt auf das Eingangsbeispiel zurück. Denn mit Sprache sei auch immer eine gewisse Intention verbunden. „Wir nutzen Sprache, um Dinge zu tun.“ Ein Satz wie „Könntest du mir das Salz reichen?“ ist tatsächlich keine Frage, die zu beantworten wäre, sondern eine Art höflicher Befehl. Wenn der Roboter dem nachkomme, habe er die Intention erfasst, also verstanden, was gemeint war. Auch das ist letztlich ein Vorhersagen – in diesem Fall nicht nur von Wortteilen, sondern von menschlichen Intentionen.
Was unterscheidet den Menschen von Sprachmodellen?
Noch sind wir Johann-Mattis List zufolge besser im spielerischen Umgang mit Sprache, bei Wortspielen etwa. Wir sind kreativer beim Lösen unvorhergesehener Situationen sowie beim Formulieren wissenschaftlicher Fragestellungen. Nur: Wie lange noch? Johann-Mattis List führt aus, dass es schwierig sei, die Fähigkeiten von LLMs zu testen. Denn jede Herausforderung verbessert ihre Fähigkeiten. Das mache es schwer, Grenzen zu definieren.
Könnten Sprachmodelle uns umgekehrt helfen, neue Fähigkeiten zu erwerben? List bezweifelt das. Studien zeigen eher: Wer sich zu sehr auf KI verlässt, denkt weniger selbst. Seine Prognose fällt düster aus: „Der steigende Einfluss von Sprachmodellen auf unser Leben wird dazu führen, dass viele von uns weniger denken, weniger verstehen, weniger verdienen – und zu mehr Langeweile.“
















