Human and robot enjoying a candlelight dinner. AI-generated image using DeepAI and ChatGPT
A human and a robot are sitting at a kitchen table. The robot is equipped with a large language model, meaning it has been trained to process human language. The human says, ‘Please pass me the salt.’ The robot does so. Did it understand the request?
No, says Professor Johann-Mattis List, Chair of Multilingual Computational Linguistics. Yes, says his colleague Dr Christian Bentz, Assistant Professor at the same chair. Their lecture was part of the public lecture series on ‘Artificial Intelligence – Between Hype and Reality’, which took place in June and July at the University of Passau.
Large language models (LLMs) process language with the help of neural networks that mimic the functioning of the human brain. Trained with huge amounts of text data, they recognise patterns, structures and connections. The fact that LLMs – such as ChatGPT from the USA or Mistral AI from Europe – are now astonishingly good at responding to human language is because language structures can apparently be calculated quite well.
Language models are con artists – the position of Professor List
For Johann-Mattis List, this remains a trick. Language models are con artists who appear convincing but do not really understand.
He refers to the thought experiment of the ‘Chinese room’ by philosopher John Searle from the 1980s. In it, a person in a closed room answers questions in Chinese – even though they don't know Chinese. They simply follow instructions in their native language. To outsiders, it appears as if they understand the language. But this is an illusion. ‘Searle's paper from back then reads like a current debate,’ says Johann-Mattis List.
In 2020, linguist Emily Bender and her colleague Alexander Koller conducted another thought experiment, the 'Octopus Experiment'. In this scenario, an intelligent deep-sea octopus secretly eavesdrops on two people communicating via an underwater cable. The octopus learns to imitate one person until one day it fails to answer a question: ‘I'm being attacked by a bear. What should I do?’ The octopus has no knowledge of bears – and thus reveals itself.
In the 1980s, American linguist Noam Chomsky argued that learning language is a fundamentally human matter. Children learn grammar even when input is limited – a phenomenon that Chomsky termed ‘poverty of the stimulus.’ Although List considers this argument outdated today, the central question remains: Does being able to automatically mean understanding? List demonstrates the idea with a live performance:

He himself can juggle certain complicated patterns, but whether he really understands these patterns in all their details is another question.
LLMs understand language better than humans, says Dr. Bentz
Let's return to the introductory example provided by linguist Dr. Christian Bentz. Bentz is a Assistant Professor at Johann-Mattis List's chair and is interested in the connection between information and language.
In his ERC project EVINE, he is investigating the first traces of visual information coding – the signs of the Palaeolithic era, some of which are up to 400,000 years old. The first signs may well have served as memory aids, many thousands of years before the development of writing.
Let's jump back to 1950. Mathematician Claude Elwood Shannon conducted an experiment with his wife and fellow researcher Betty. She was asked to continuously guess the letters in sentences. She used her natural linguistic intuition as a native English speaker. The research couple developed a method for calculating the information density of the English language. Shannon defined entropy as a measure of information content and uncertainty.
Modern language models have perfected the ability to predict linguistic utterances – and thus minimise entropy. They calculate probabilities: Which word comes next? According to Dr. Bentz, they are better at this than humans – and not just in English. With an international team, he has used entropy and redundancy to compare patterns in languages worldwide. While there are clear differences in the distribution of characters and words, the entropy values of subwords in very different languages are surprisingly similar:
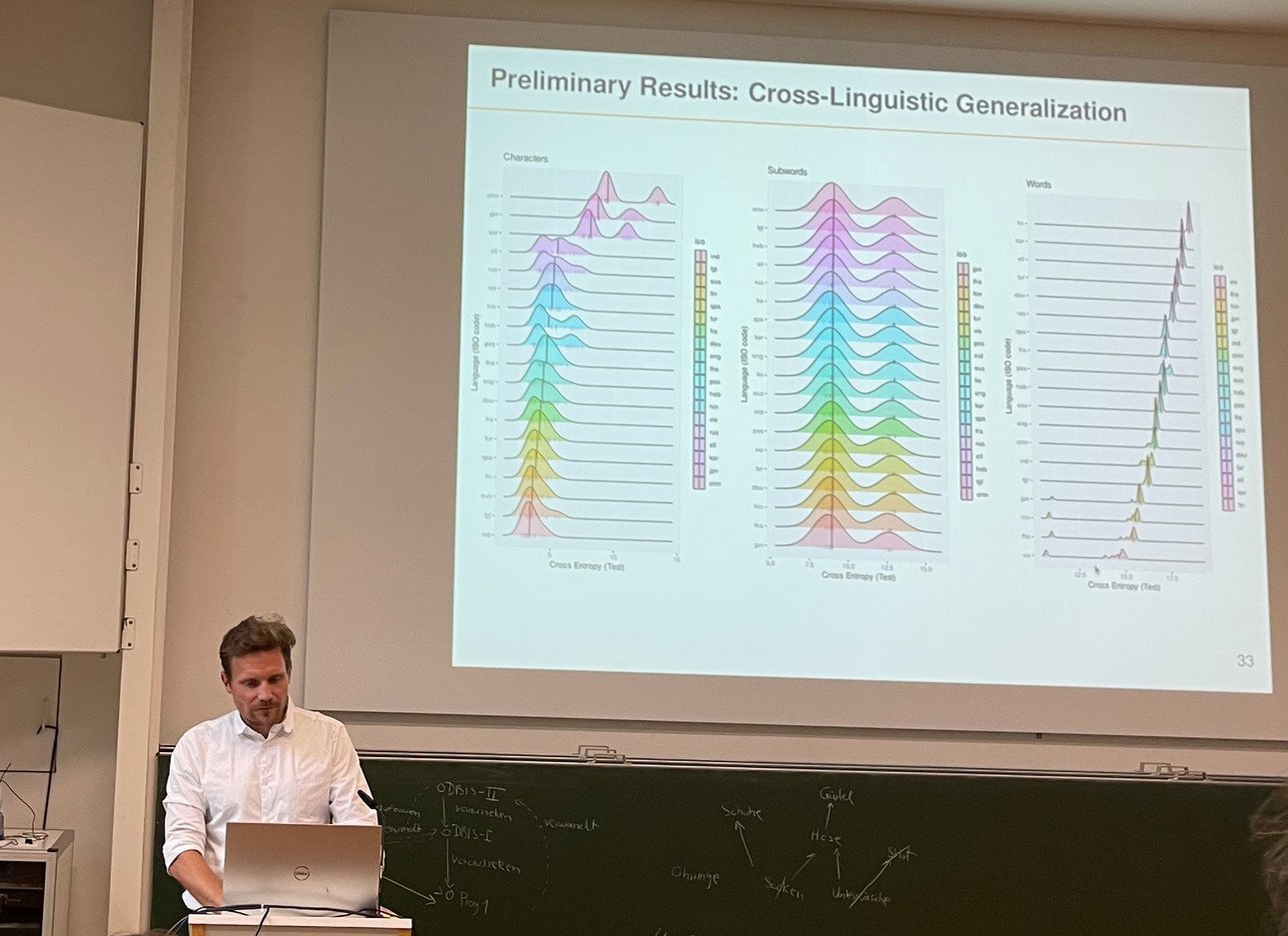
His conclusion: completely different languages can be calculated and modelled using the same methods. This would mean that large language models could at least predict languages better than humans. But is statistically accurate prediction the same as understanding?
Dr Bentz returns to the initial example. Language always has a certain intention behind it. ‘We use language to do things.’
A sentence such as ‘Could you pass me the salt?’ is not actually a question that needs to be answered, but rather a kind of polite command. If the robot complies, it has understood the intention, i.e. what was meant. Ultimately, this is also a prediction – in this case, not only of parts of words, but of human intentions.
What distinguishes humans from LLMs?
According to Johann-Mattis List, we are still better at playing with language, for example in puns. We are more creative in solving unexpected situations and formulating scientific questions. But for how much longer? Johann-Mattis List explains that it is difficult to test the capabilities of LLMs because every challenge improves their abilities. This makes it difficult to define their limits.
Could language models help us acquire new skills? List doubts it. Studies tend to show that people who rely too much on AI tend to think less for themselves. His prognosis is bleak: ‘The growing influence of language models on our lives will lead to many of us thinking less, understanding less, earning less – and feeling more bored.’














![[Translate to Englisch:]](/fileadmin/_processed_/5/d/csm_IMG_3780_e5d58f2d3f.jpg "[Translate to Englisch:]")

